從Kubernetes到Cloud Native——雲原生應用之路
本文簡要介紹了容器技術發展的路徑,為何Kubernetes的出現是容器技術發展到這一步的必然選擇,而為何Kuberentes又將成為雲原生應用的基石。
我的分享按照這樣的主線展開:容器->Kubernetes->微服務->Cloud Native(雲原生)->Service Mesh(服務網格)->使用場景->Open Source(開源)。
容器
容器最初是通過開發者工具而流行,可以使用它來做隔離的開發測試環境和持續集成環境,這些都是因為容器輕量級,易於配置和使用帶來的優勢,docker和docker-compose這樣的工具極大的方便的了應用開發環境的搭建,開發者就像是化學家一樣在其中小心翼翼的進行各種調試和開發。
隨著容器的在開發者中的普及,已經大家對CI流程的熟悉,容器周邊的各種工具蓬勃發展,儼然形成了一個小生態,在2016年達到頂峰,下面這張是我畫的容器生態圖:
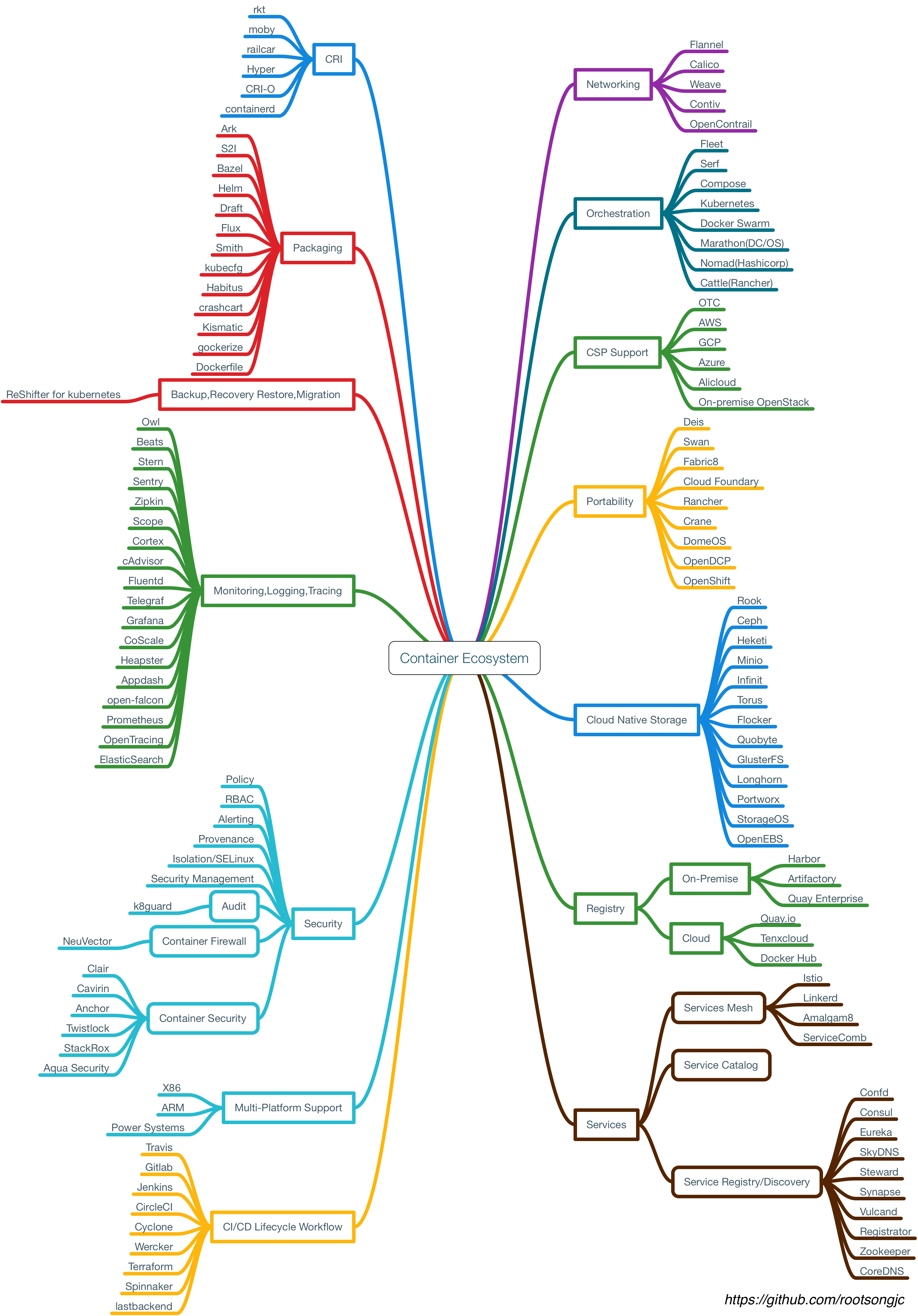
該生態涵蓋了容器應用中從鏡像倉庫、服務編排、安全管理、持續集成與發布、存儲和網絡管理等各個方面,隨著在單主機中運行容器的成熟,集群管理和容器編排成為容器技術亟待解決的問題。譬如化學家在實驗室中研究出來的新產品,如何推向市場,進行大規模生產,成了新的議題。
為什麼使用Kubernetes
Kubernetes是容器編排系統的事實標準
在單機上運行容器,無法發揮它的最大效能,只有形成集群,才能最大程度發揮容器的良好隔離、資源分配與編排管理的優勢,而對於容器的編排管理,Swarm、Mesos和Kubernetes的大戰已經基本宣告結束,kubernetes成為了無可爭議的贏家。
下面這張圖是Kubernetes的架構圖(圖片來自網絡),其中顯示了組件之間交互的接口CNI、CRI、OCI等,這些將Kubernetes與某款具體產品解耦,給用戶最大的定製程度,使得Kubernetes有機會成為跨雲的真正的雲原生應用的操作系統。
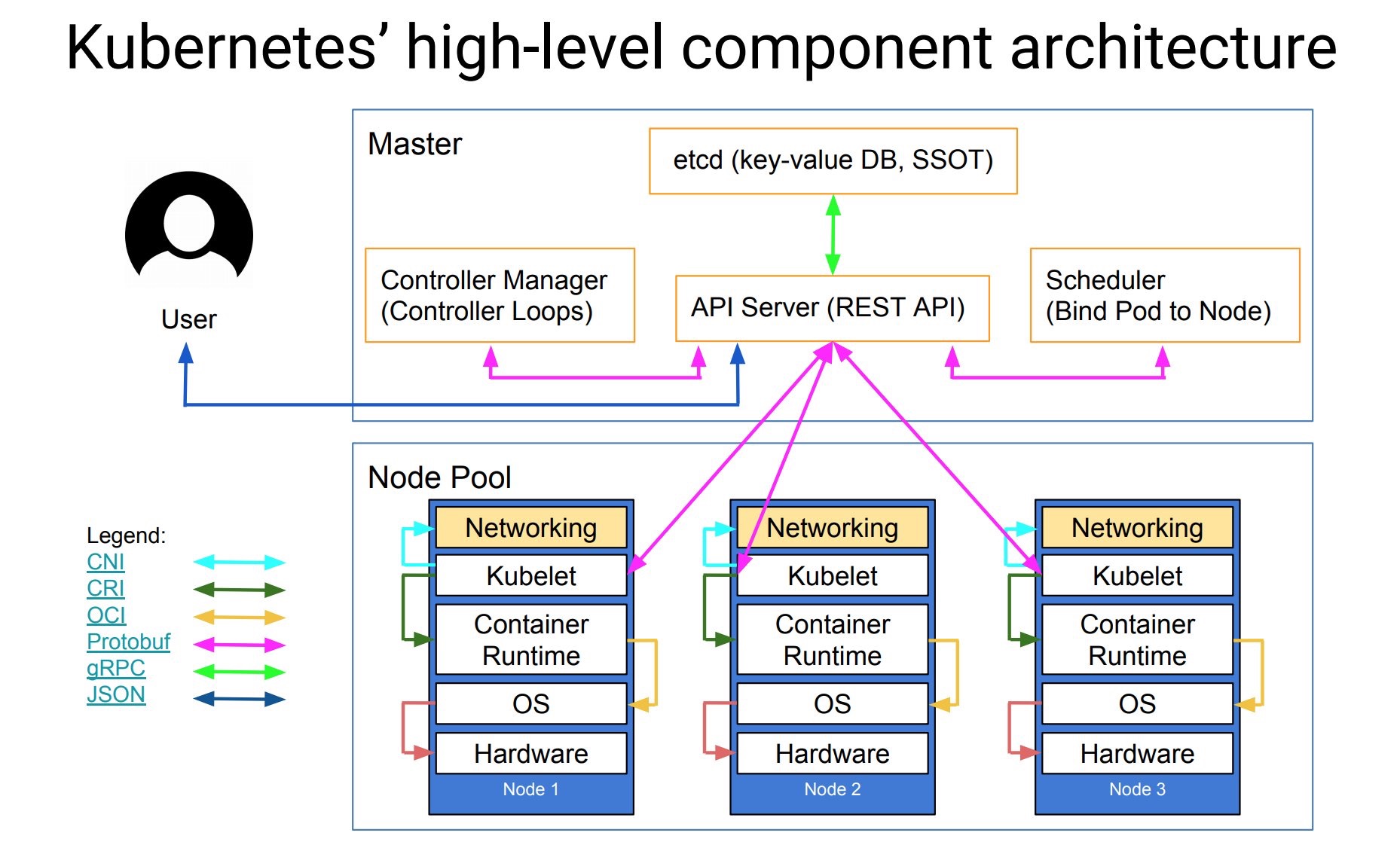
隨著Kubernetes的日趨成熟,“Kubernetes is becoming boring”,基於該“操作系統”之上構建的適用於不同場景的應用將成為新的發展方向,就像我們將石油開采出來後,提煉出汽油、柴油、瀝青等等,所有的材料都將找到自己的用途,Kubernetes也是,畢竟我們誰也不是為了部署和管理容器而用Kubernetes,承載其上的應用才是價值之所在。
雲原生的核心目標
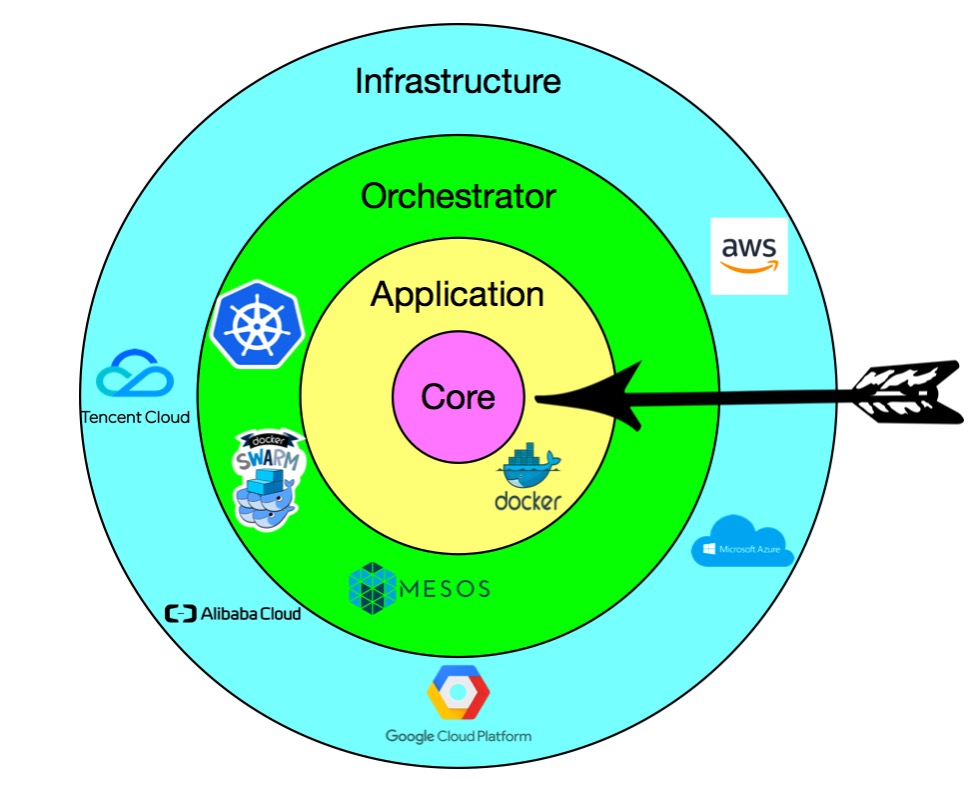
雲已經可以為我們提供穩定可以唾手可得的基礎設施,但是業務上云成了一個難題,Kubernetes的出現與其說是從最初的容器編排解決方案,倒不如說是為了解決應用上雲(即云原生應用)這個難題。
包括微服務和FaaS/Serverless架構,都可以作為雲原生應用的架構。
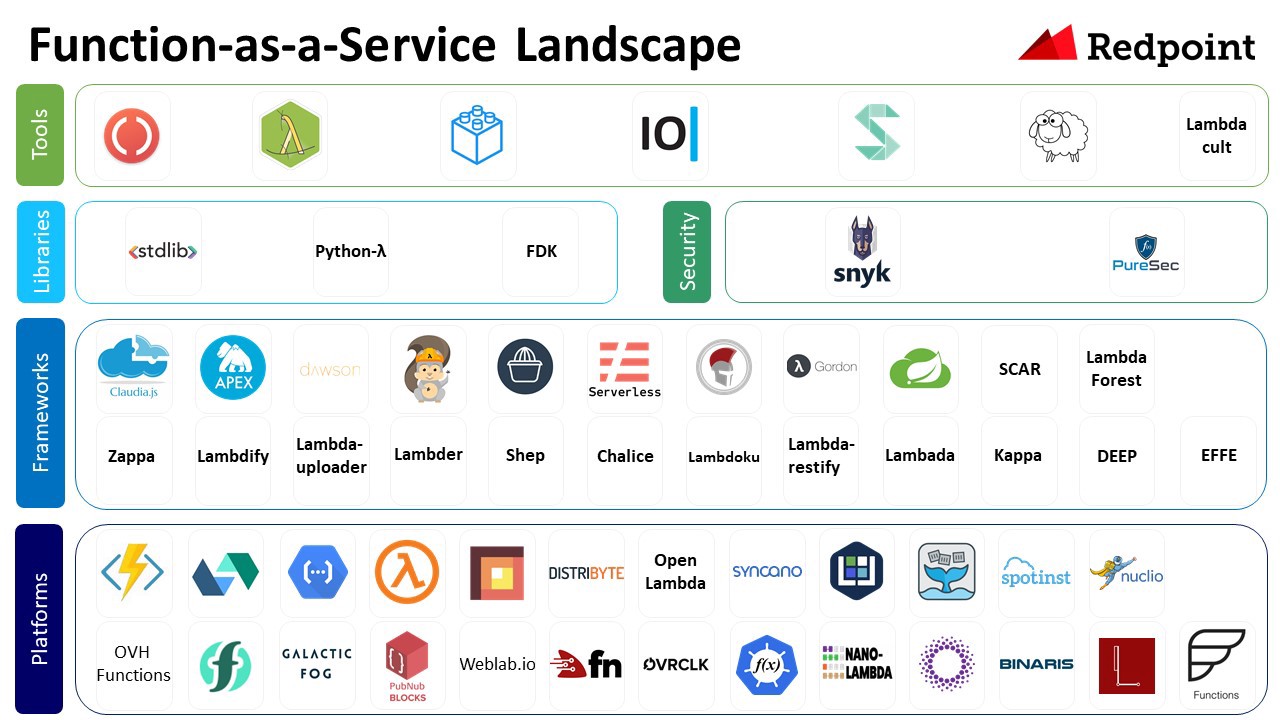
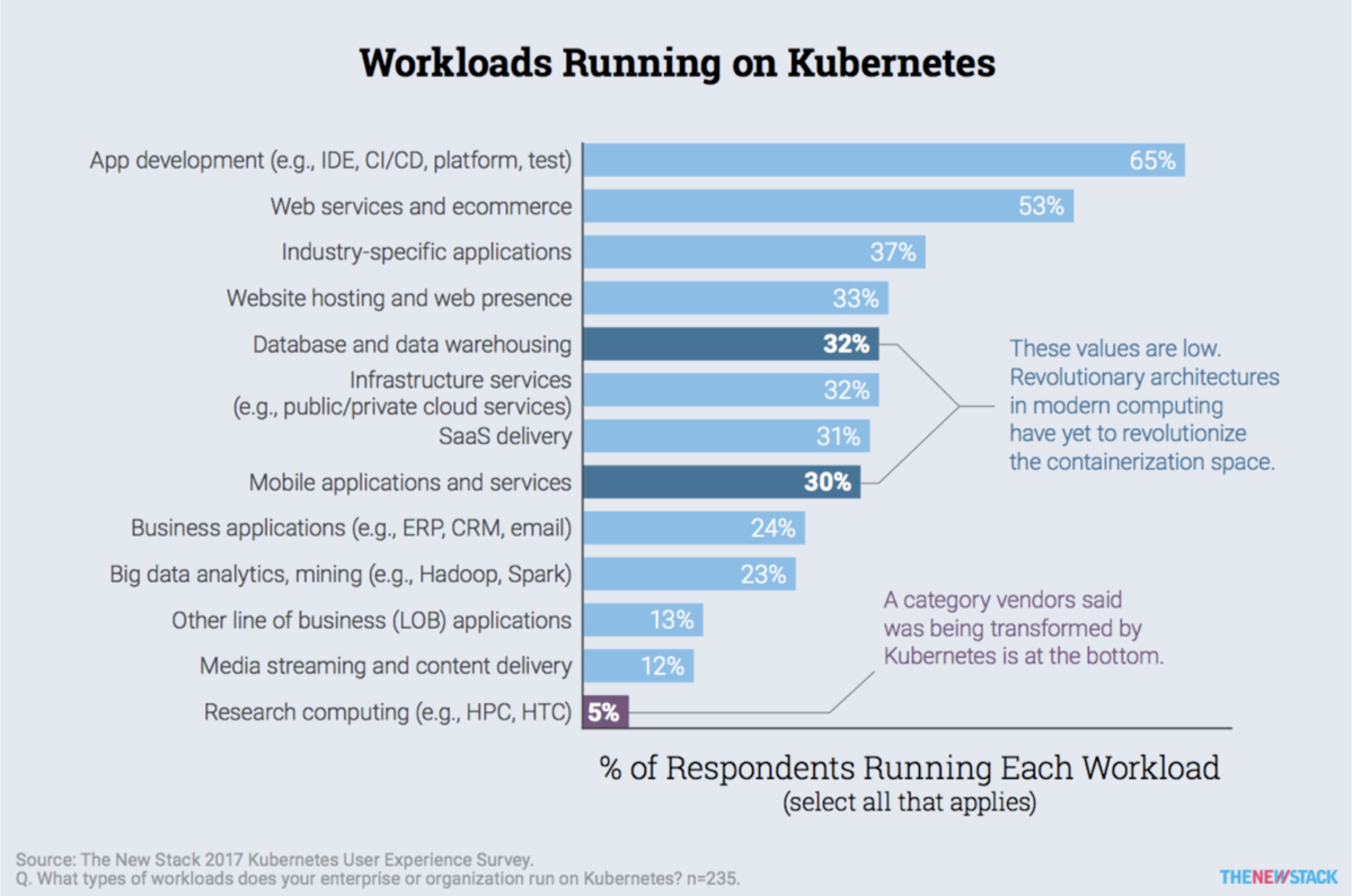
另外基於Kubernetes的構建PaaS平台和Serverless也處於爆發的準備的階段,如下圖中Gartner的報告中所示:
當前各大公有云如Google GKE、微軟Azure ACS、亞馬遜EKS(2018年上線)、VmWare、Pivotal、騰訊雲、阿里雲等都提供了Kuberentes服務。
微服務
微服務——Cloud Native的應用架構。
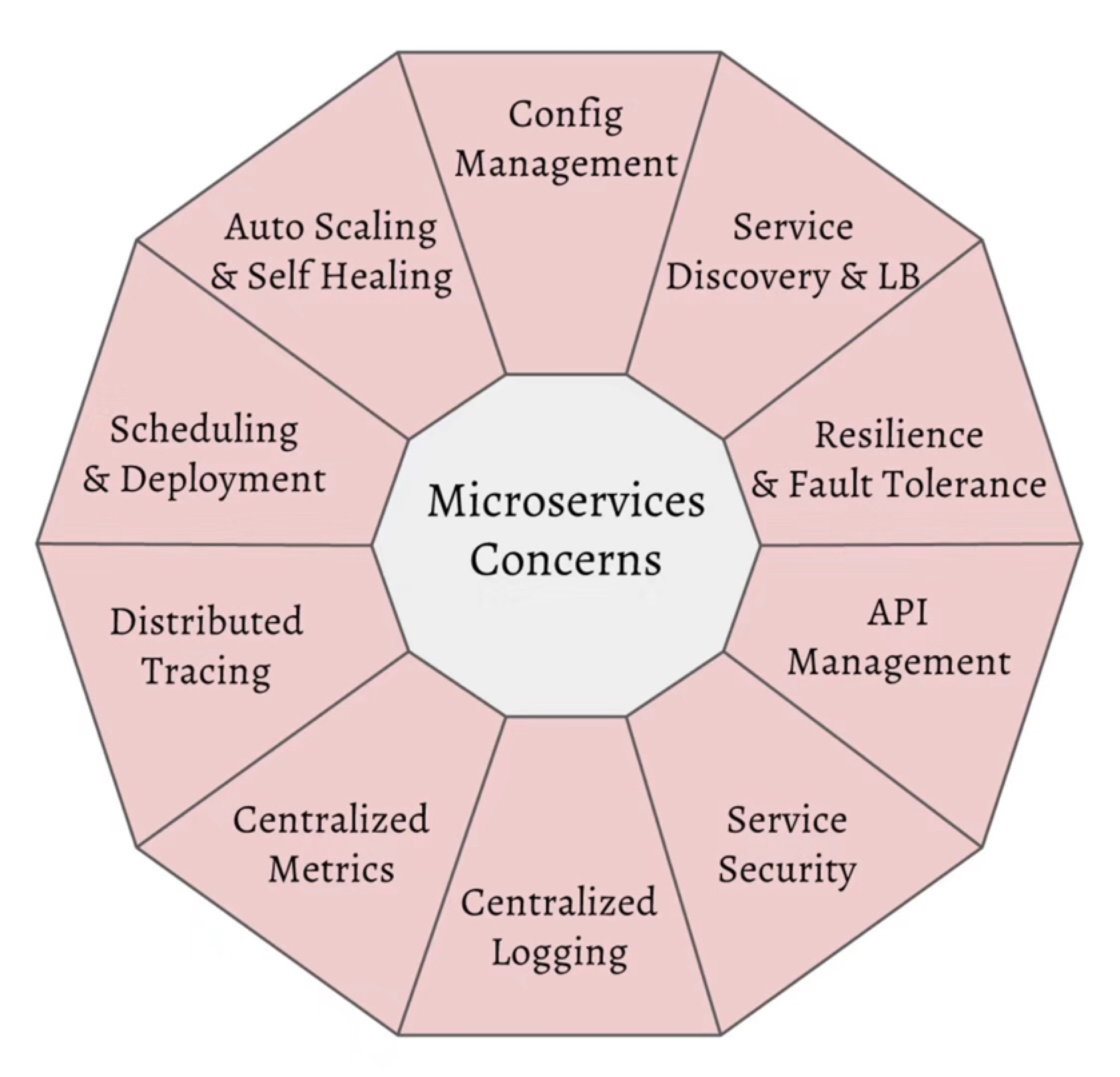
微服務帶給我們很多開發和部署上的靈活性和技術多樣性,但是也增加了服務調用的開銷、分佈式系統管理、調試與服務治理方面的難題。
當前最成熟最完整的微服務框架可以說非Spring莫屬,而Spring又僅限於Java語言開發,其架構本身又跟Kubernetes存在很多重合的部分,如何探索將Kubernetes作為微服務架構平台就成為一個熱點話題。
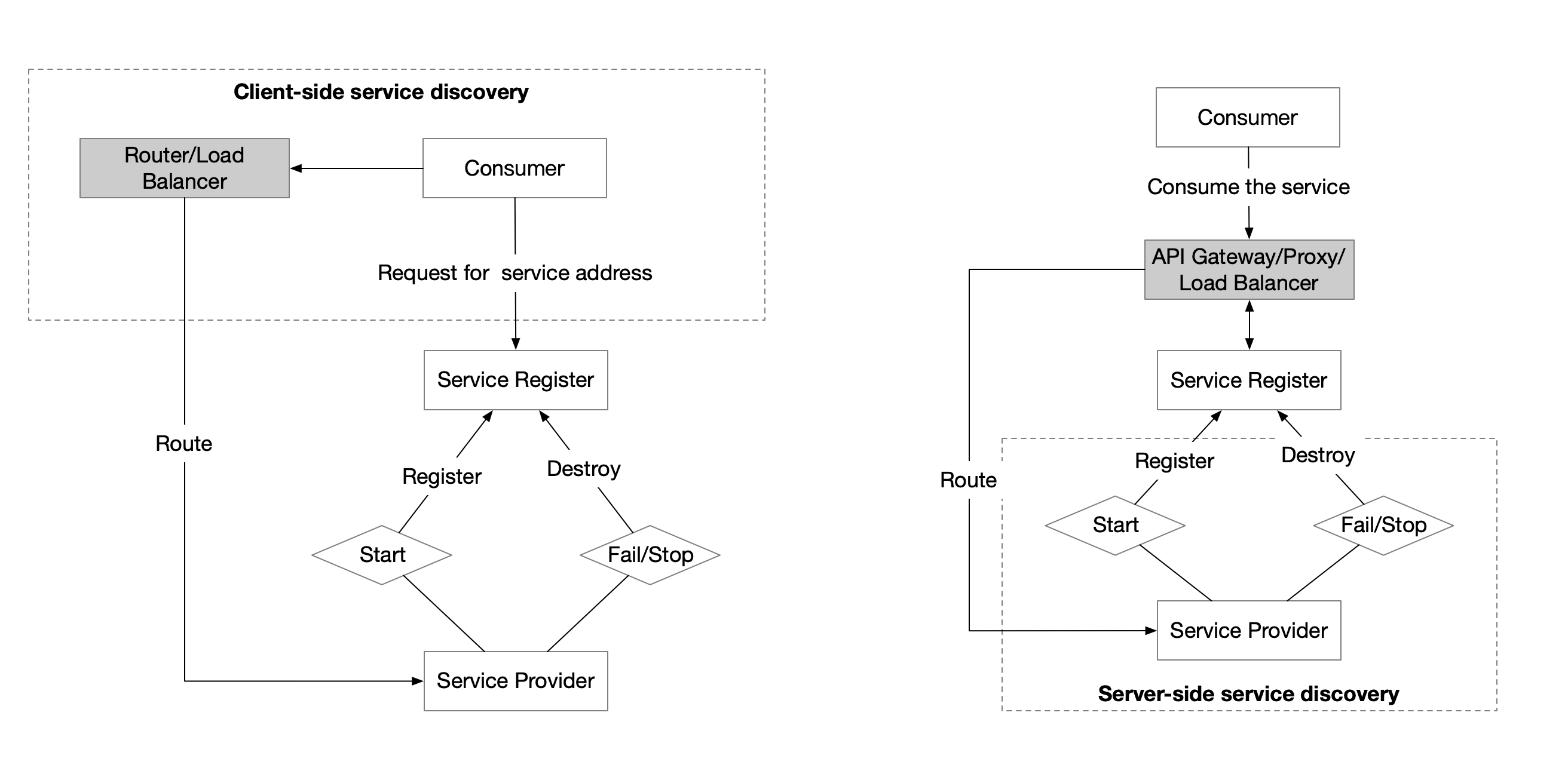
就拿微服務中最基礎的服務註冊發現功能來說,其方式分為客戶端服務發現和服務端服務發現兩種,Java應用中常用的方式是使用Eureka和Ribbon做服務註冊發現和負載均衡,這屬於客戶端服務發現,而在Kubernetes中則可以使用DNS、Service和Ingress來實現,不需要修改應用代碼,直接從網絡層面來實現。
Cloud Native
DevOps——通向雲原生的雲梯

CNCF(雲原生計算基金會)給出了雲原生應用的三大特徵:
- 容器化包裝:軟件應用的進程應該包裝在容器中獨立運行。
- 動態管理:通過集中式的編排調度系統來動態的管理和調度。
- 微服務化:明確服務間的依賴,互相解耦。
下圖是我整理的關於雲原生所需要的能力和特徵。
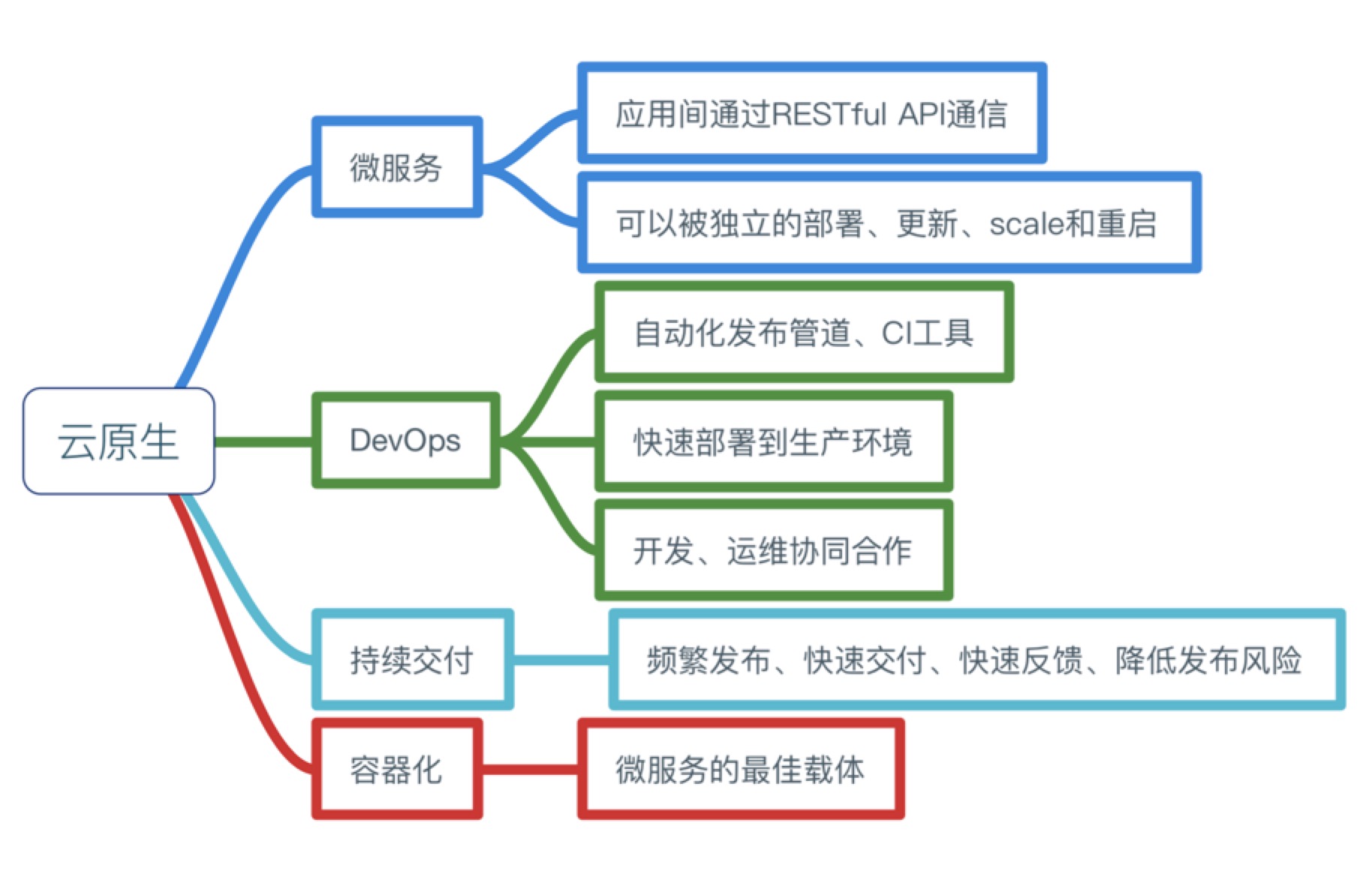

使用Kubernetes構建雲原生應用
- 基準代碼
- 依賴管理
- 配置
- 後端服務
- 構建,發布,運行
- 無狀態進程
- 端口綁定
- 並發
- 易處理
- 開發環境與線上環境等價
- 日誌作為事件流
- 管理進程
另外還有補充的三點:
- API聲明管理
- 認證和授權
- 監控與告警
如果落實的具體的工具,請看下圖,使用Kubernetes構建雲原生架構:
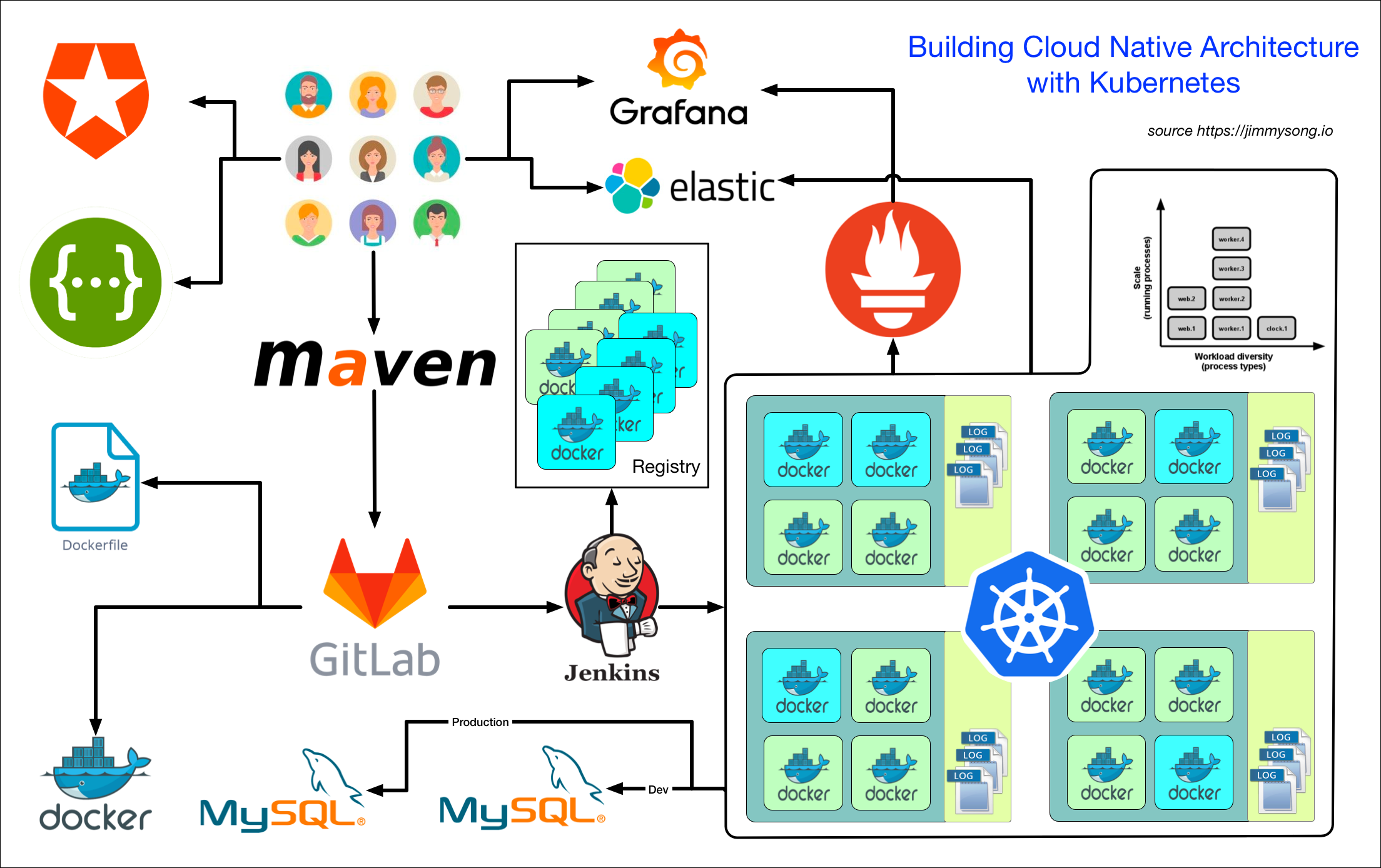
結合這12因素對開發或者改造後的應用適合部署到Kubernetes之上,基本流程如下圖所示:
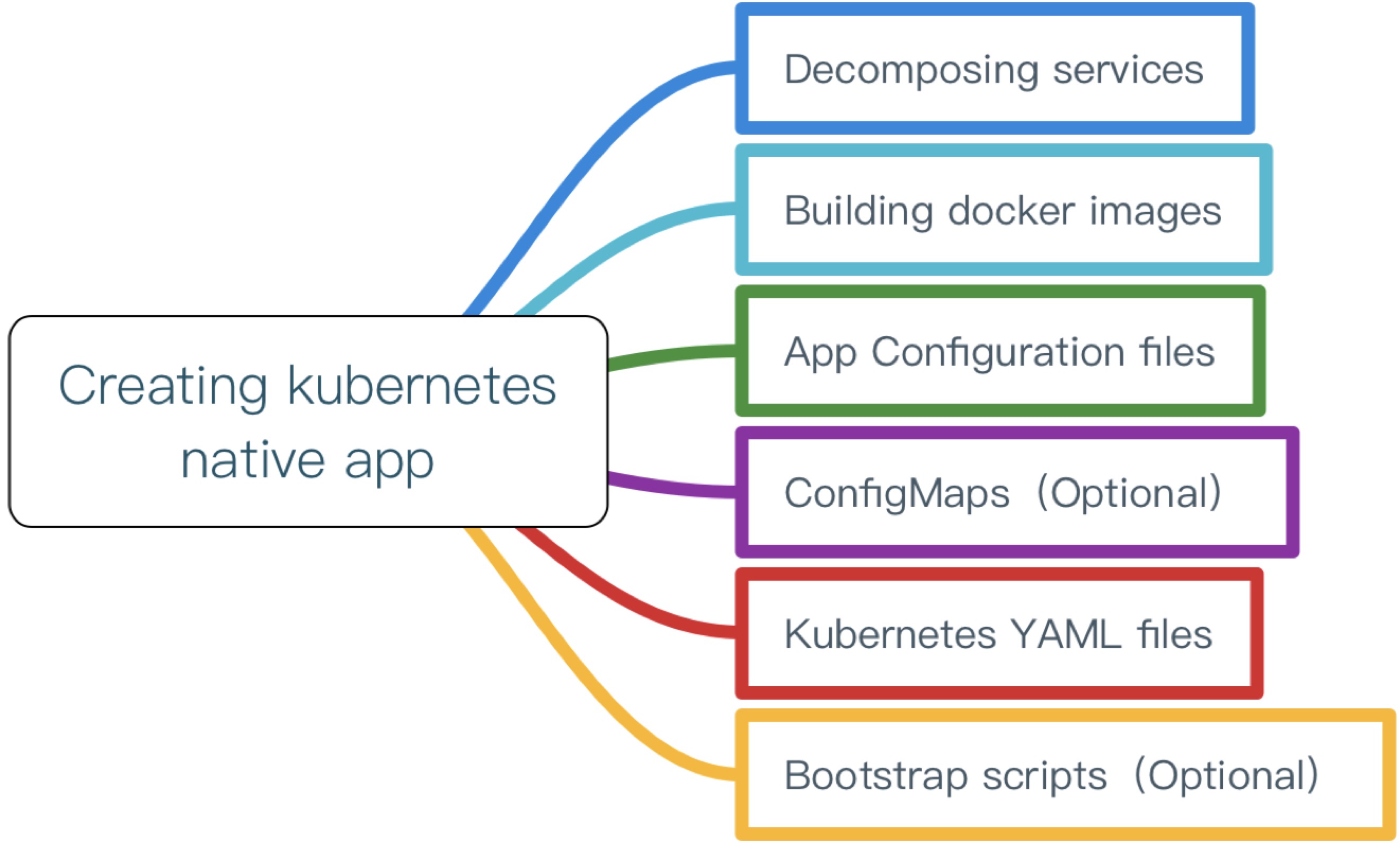
遷移到雲架構
Service Mesh
Kubernetes中的應用將作為微服務運行,但是Kuberentes本身並沒有給出微服務治理的解決方案,比如服務的限流、熔斷、良好的灰度發布支持等。
Service mesh可以用來做什麼
- Traffic Management:API網關
- Observability:服務調用和性能分析
- Policy Enforcment:控制服務訪問策略
- Service Identity and Security:安全保護
Service mesh的特點
- 專用的基礎設施層
- 輕量級高性能網絡代理
- 提供安全的、快速的、可靠地服務間通訊
- 擴展kubernetes的應用負載均衡機制,實現灰度發布
- 完全解耦於應用,應用可以無感知,加速應用的微服務和雲原生轉型
使用Service Mesh將可以有效的治理Kuberentes中運行的服務,當前開源的Service Mesh有:
- Linkderd:https://linkerd.io,由最早提出Service Mesh的公司Buoyant開源,創始人來自Twitter
- Envoy:https://www.envoyproxy.io/,Lyft開源的,可以在Istio中使用Sidecar模式運行
- Istio:https://istio.io,由Google、IBM、Lyft聯合開發並開源
- Conduit:https://conduit.io,同樣由Buoyant開源的輕量級的基於Kubernetes的Service Mesh
Istio VS Linkerd
Linkerd和Istio是最早開源的Service Mesh,它們都支持Kubernetes,下面是它們之間的一些特性對比。
| Feature | Istio | Linkerd |
|---|---|---|
| 部署架構 | Envoy/Sidecar | DaemonSets |
| 易用性 | 複雜 | 簡單 |
| 支持平台 | kuberentes | kubernetes/mesos/Istio/local |
| 當前版本 | 0.3.0 | 1.3.3 |
| 是否已有生產部署 | 否 | 是 |
關於兩者的架構可以參考各自的官方文檔,我只從其在kubernetes上的部署結構來說明其區別。
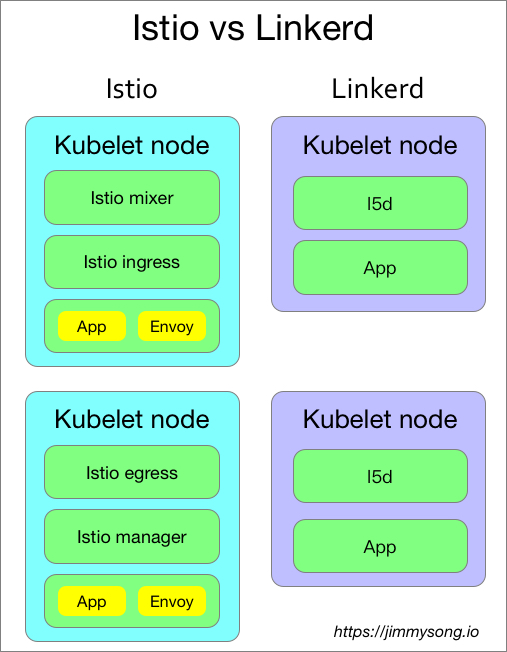
Istio的組件複雜,可以分別部署的kubernetes集群中,但是作為核心路由組件Envoy是以Sidecar形式與應用運行在同一個Pod中的,所有進入該Pod中的流量都需要先經過Envoy。
使用場景
Cloud Native的大規模工業生產

GitOps
給開發者帶來最大配置和上線的靈活性,踐行DevOps流程,改善研發效率,下圖這樣的情況將更少發生。
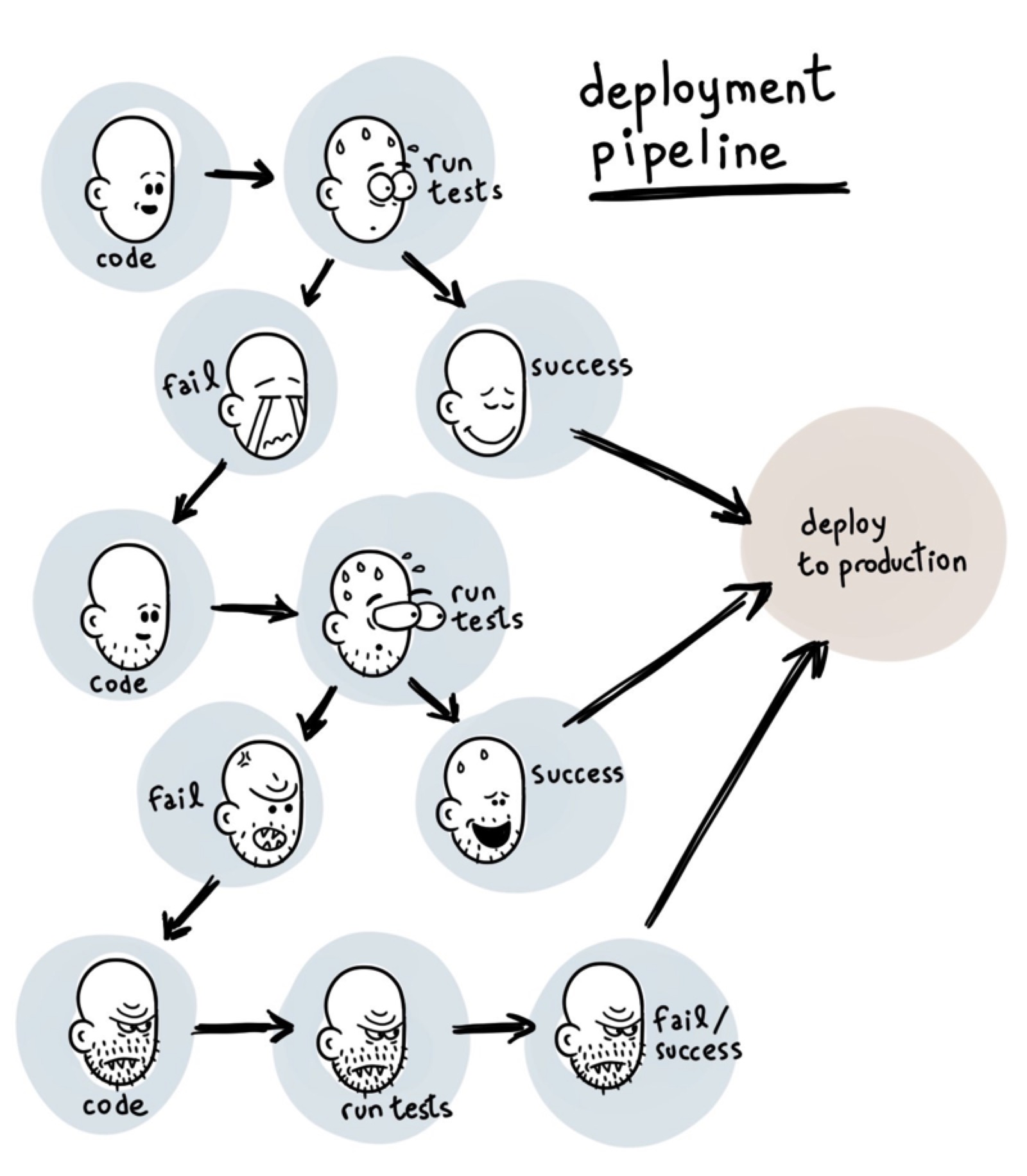
我們知道Kubernetes中的所有應用的部署都是基於YAML文件的,這實際上就是一種Infrastructure as code,完全可以通過Git來管控基礎設施和部署環境的變更。
Big Data
Spark現在已經非官方支持了基於Kuberentes的原生調度,其具有以下特點:
- Kubernetes原生調度:與yarn、mesos同級
- 資源隔離,粒度更細:以namespace來劃分用戶
- 監控的變革:單次任務資源計量
- 日誌的變革:pod的日誌收集
| Feature | Yarn | Kubernetes |
|---|---|---|
| queue | queue | namespace |
| instance | ExcutorContainer | Executor Pod |
| network | host | plugin |
| heterogeneous | no | yes |
| security | RBAC | ACL |
下圖是在Kubernetes上運行三種調度方式的spark的單個節點的應用部分對比:
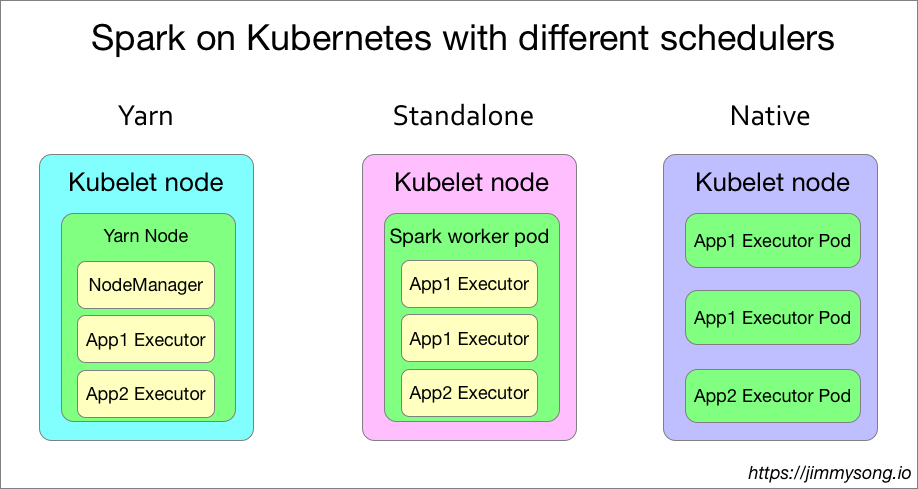
從上圖中可以看到在Kubernetes上使用YARN調度、standalone調度和kubernetes原生調度的方式,每個node節點上的Pod內的spark Executor分佈,毫無疑問,使用kubernetes原生調度的spark任務才是最節省資源的。
提交任務的語句看起來會像是這樣的:
./spark-submit \
--deploy-mode cluster \
--class com.talkingdata.alluxio.hadooptest \
--master k8s://https://172.20.0.113:6443 \
--kubernetes-namespace spark-cluster \
--conf spark.kubernetes.driverEnv.SPARK_USER=hadoop \
--conf spark.kubernetes.driverEnv.HADOOP_USER_NAME=hadoop \
--conf spark.executorEnv.HADOOP_USER_NAME=hadoop \
--conf spark.executorEnv.SPARK_USER=hadoop \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \
--conf spark.driver.memory=100G \
--conf spark.executor.memory=10G \
--conf spark.driver.cores=30 \
--conf spark.executor.cores=2 \
--conf spark.driver.maxResultSize=10240m \
--conf spark.kubernetes.driver.limit.cores=32 \
--conf spark.kubernetes.executor.limit.cores=3 \
--conf spark.kubernetes.executor.memoryOverhead=2g \
--conf spark.executor.instances=5 \
--conf spark.app.name=spark-pi \
--conf spark.kubernetes.driver.docker.image=spark-driver:v2.1.0-kubernetes-0.3.1-1 \
--conf spark.kubernetes.executor.docker.image=spark-executor:v2.1.0-kubernetes-0.3.1-1 \
--conf spark.kubernetes.initcontainer.docker.image=spark-init:v2.1.0-kubernetes-0.3.1-1 \
--conf spark.kubernetes.resourceStagingServer.uri=http://172.20.0.114:31000 \
~/Downloads/tendcloud_2.10-1.0.jar
關於支持Kubernetes原生調度的Spark請參考:https://jimmysong.io/spark-on-k8s/
Open Source
Contributing is Not only about code, it is about helping a community.
下圖是我們剛調研準備使用Kubernetes時候的調研方案選擇。
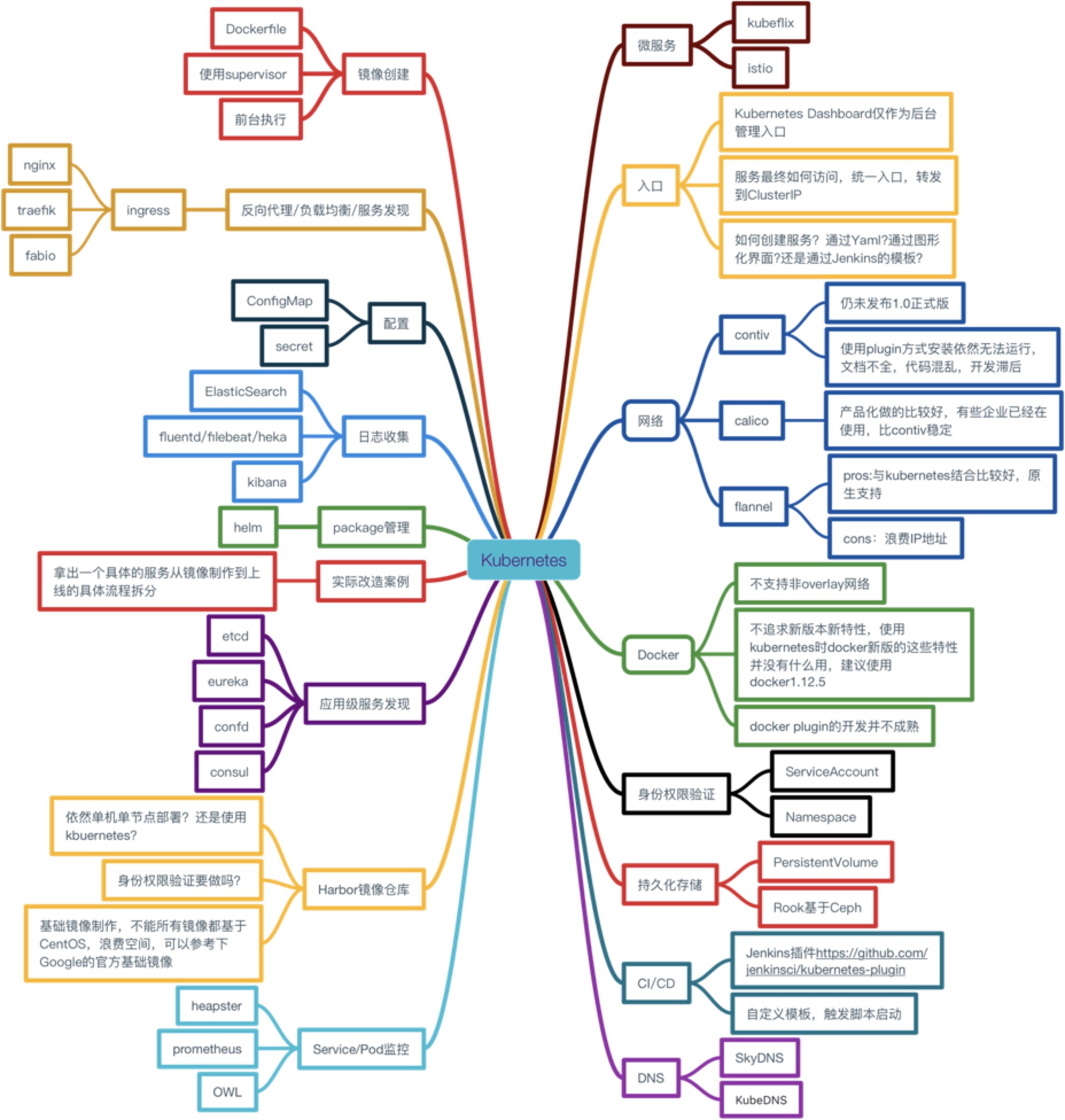
對於一個初次接觸Kubernetes的人來說,看到這樣一個龐大的架構選型時會望而生畏,但是Kubernetes的開源社區幫助了我們很多。
Reference: https://jimmysong.io/posts/from-kubernetes-to-cloud-native/

留言
張貼留言